Reading through all of Jeff Bezos’ annual letters inspired me to read through other letters from very smart people—and Larry Page and Sergey Brin from Google were the first choice. Besides using a bunch of Google services on a daily basis, I’ve never followed them as a public company so I learned a lot reading the letters. The main thing I came away with is an appreciation of how Google has evolved from just a search engine to a smorgasbord of many products and services that all ultimately feed into the search funnel.
If you invested in Google in 1998 (as a private company), you almost certainly would have been betting on their ability to build a search engine. In fact, you can read Larry and Sergey’s original paper from 1998 describing their Google prototype and, not surprisingly, there is no mention of Gmail, Analytics, Chrome, YouTube, Maps, or Android. It’s interesting that, in my opinion, Google’s expansion into so many products would have been impossible to predict, but looking back from today it all seems rather obvious.
Google’s main product has always been search. The more data Google has, the better they make search. But search is free. So they support search by making money from advertising. And the money they make from advertising allows them to improve search and then to build other products that acquire more data (and that data also improves search).

As they gather data, search will be improved and thus ads on their site will be more valuable. I think the most interesting segment of that above flywheel is the “more money to spend acquiring data” part. They’ve expanded into so many tangential products and all of them go back into feeding the flywheel of improved search and ads.
With ads being their main revenue source, it made sense to think that the companies buying their ads would spend more money if Google could prove to them how well their ads were performing. Thus, Analytics was born (actually it was acquired).
“We really want our customers to track conversions and the performance of their advertising, because when they do, they make more informed bids in our ads auction.”
E-commerce companies could optimize their sites so much easier after Analytics was born. Analytics helps websites ensure their customers can find what they are looking for and complete a transaction. And once an Internet user clicks on an ad, navigates a website, and decides they want to purchase something, a simplified checkout process will help close the deal. Thus, Google Checkout was born (which eventually became Google Wallet). If websites are easier to navigate and checkout processes are seamless, those e-commerce companies will make more money, see a higher ROI on their ad spending, and buy more Google ads in the future.
Likewise, when Chrome was launched in 2008 the average browser was much worse than it is today. When Google is dependent on people using the Internet and the main products that people use to access the Internet suck, it makes sense for Google to build a better browser. If people can browse the Internet faster, more reliably, and safer than before, they’ll do more searches and click on more ads and visit more websites and buy more things—thus proving the value of Google ads.
Another way for Google to get more people to use their products is to get more people on the Internet (there are still more than four billion people in the world who don’t have access to the Internet). This explains Project Loon—their moonshot idea to get Internet access to remote areas in developing countries. If Google can get more people using the Internet, there’s a good chance a large percentage of those people will use Google products and help their flywheel. This is similar logic to their Fiber initiative. Even though it’s hit some roadblocks, it still makes sense from the perspective of getting more people online and getting people faster Internet. If browsing the Internet is faster and more seamless than it is today, more people will use it more often.
The same logic goes for so many of their other major products. YouTube gives them data on people’s video watching preferences (and another platform to serve ads on). Maps gives them travel data that is very localized. Gmail gives them data about all kinds of stuff that shows up in our emails (like events and travel that they automatically add to our calendars for us). Google+, even though it hasn’t been nearly as successful as many people thought, helps Google understand people’s relationships and their connections to others.
The previous several paragraphs all seem like very logical (and even obvious) extensions of a business that makes money through ads on their search product. Even so, I’m betting very few investors predicted the different areas that Google would expand into. I’d love to read some Google investment write-ups from the mid-2000s, but I haven’t been able to find any (the oldest one on VIC is from 2009, which is well done in my opinion—it mostly focuses on Google’s long-term competitive advantages).
It’s amazing to me that someone who invested in Google in the late 90s would have been betting on one thing, yet they would have made millions of dollars on tangential things that they never would have seen coming. Being able to think through possible second and third order effects of certain business models can be highly rewarding in investing, but it’s extremely difficult.
Another common example is Amazon Web Services (AWS). Looking back from today’s viewpoint, the evolution of AWS seems rather obvious. Think about it from the perspective of an Amazon investor in the year 2000: Amazon is quickly becoming America’s largest e-commerce company. Given they’re the first massive e-commerce company, they probably have very large computing demands that third parties aren’t prepared to handle for them. Thus, they’ll have to solve the problem themselves and create their own computing services. If they are able to satisfy the demand of the largest e-commerce company in the world (themselves), surely they could also support the computing demands of many other e-commerce companies that are growing quickly.
But I’m betting that no one who invested in Amazon in the year 2000 made it through that rather simple thought process because it would have been nearly impossible at the time. And now AWS is a very significant portion of Amazon’s value.
I’ve talked before about the idea of unknown upside optionality and I think Chrome, Maps, AWS, and many other products these two companies offer are perfect examples of it. The highest quality companies seem to create value in totally unexpected ways, whereas low quality companies seem to destroy value in unpredictable ways (i.e. they have more unknown downside optionality to them).
Of the companies I own, I think Where Food Comes From has the most unknown upside optionality. I believe they have opportunities to expand into all kinds of tangential markets that they aren’t yet in. Just this past year they started auditing flower growers and dog breeders. If you asked me a year ago what markets they might expand into, I never would have mentioned either of those, but as soon as I saw the announcement I thought “duh, those are obvious extensions of their core business.”
I don’t know if I have a final point to be made here, other than how hard investing is. The least quantifiable aspects of an investment are the most important, yet they’re the hardest to predict. When I’m looking at a potential investment, how do I put a value on “possibility of doing good things that I can’t possibly predict?”
Random fun findings from the Google letters
Net neutrality
I didn’t expect to find a rant about net neutrality in one of their old shareholder letters, but sure enough they wrote about it in the 2005 letter. Unfortunately, this is still a hot button issue today.
“Now, however, there is a movement among companies that carry Internet traffic to shatter those freedoms and discriminate between the bits they carry. In the future, for example, they might want to exercise control over which VOIP phone provider you use. Perhaps they’ll prevent Google from serving you video, so they can have an advantage for their own service – or for anyone who pays them more. Google will likely weather whatever happens with this issue because we have a lot of resources. But I do think there is a huge risk that consumers will not be able to access everything freely on the Internet, and that future innovation will be harmed if these changes are adopted. We are working hard to protect the open Internet and keep it from being balkanized solely for the financial benefit of a few companies that are already collecting very substantial revenue from consumers.”
The first website ever
The 2008 letter talked about the first website ever, which is fun to poke around on for a few minutes. I love their description for the Internet: “The WorldWideWeb (W3) is a wide-area hypermedia information retrieval initiative aiming to give universal access to a large universe of documents.” I’d say they’re doing pretty well on their original goal 🙂
Larry and Sergey’s original paper describing Google
Through reading about random Google stuff, I came across Larry and Sergey’s original paper from 1998 for “a large-scale hypertextual web search engine.” It’s interesting to read about their original thoughts on why Google was better than the available search engines at the time. It mostly revolved around their innovative idea to focus search results on web pages that have other web pages linking to them. In hindsight, this was a genius idea that worked well, but it was a novel idea at the time.
“Another intuitive justification is that a page can have a high PageRank if there are many pages that point to it, or if there are some pages that point to it and have a high PageRank. Intuitively, pages that are well cited from many places around the web are worth looking at. Also, pages that have perhaps only one citation from something like the Yahoo! homepage are also generally worth looking at. If a page was not high quality, or was a broken link, it is quite likely that Yahoo’s homepage would not link to it. PageRank handles both these cases and everything in between by recursively propagating weights through the link structure of the web.”
This is the original diagram showing Google’s architecture:
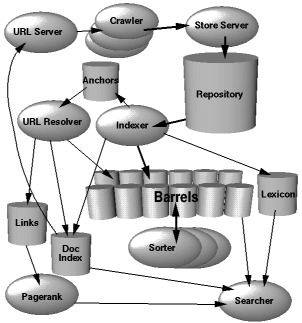
You can read the original paper here (I can’t link directly to the paper for some reason: you have to click through to “contents page of the proceedings” and then click on their paper under “Search and indexing techniques I”).
Googol
Finally, I Googled “how big of a number is googol” and came across this fascinating video that describes how big a googol and a googolplex are (a googolplex is 10 raised to the power of googol). Numbers like this are impossible for me to comprehend (to give you an idea of the scale, the analogy involves multiples universes), but it’s still a fun video to watch.
